徒然なるままに 99年02月11日
OCRソフト編
OCRを実行する手順にそって、ソフトの使い方などを説明していきたいと思います。
- まずは、原稿をスキャナにセットします
読み取りたい原稿をスキャナに斜めにならないようにセットします。
自動的にスキャンメニューが表示されますので「OCR」のアイコンをクリックしてください。
OCRソフトである「超整理er」が立ち上がります。
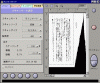 続いて、原稿の読み取りを行います
続いて、原稿の読み取りを行います
 をクリックします。
をクリックします。
すると、原稿を読み取るためのTWAINドライバーの画面が出てきます。
スキャンモード:ラインアート、解像度:400DPIにするのが、ポイントです。
不鮮明や、白黒の反転などは「フィルター」タブで調整します。
- 読みこむと、イメージがこの画面のように表示されます。
これを、テキスト文書にするには、イメージのアイコンを にドロップします。
にドロップします。
デフォルトの設定では、自動的に段組などを認識して、テキスト化する領域が指定されます。
- 領域が適切に指定されていることを確認したら、「認識」を行います。
結果は画面が分割されて表示されます。
OCR結果を確認すると、カタカナや数字・アルファベットなどの文字種によって文字色が変わっています。
これを参考にしながら、不適切な文字を修正していきます。
- 誤認識文字の修正
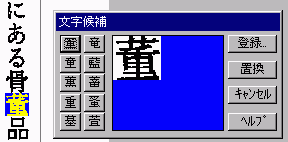 認識された文字に誤りがある場合には、テキスト表示されている文字のほうをダブルクリックしてください。右図のような選択画面が現れますので、適切な文字を選択してください。
認識された文字に誤りがある場合には、テキスト表示されている文字のほうをダブルクリックしてください。右図のような選択画面が現れますので、適切な文字を選択してください。
もし、対象となっていない場合には、キーボードから入力してください。
- 保存
修正が終わったら、ファイルメニューから「戻る」を選択します。
超整理erにイメージとテキストが保存されます。
テキストファイルとして、保存する場合にはファイルメニューより「エクスポート」します。
実際に使用した感想としては、スペックどおり、漢字は第2水準までは結構認識するようで、修正を要した文字は、非常に少ないものでした。
「品」を「。皿」としたのには、ちょっと笑いましたが・・・・
しかし、雑誌などのようにバックに写真や柄の入ったものは、人間が見ても見難いように、OCRソフトにとっても、不得手なようでかなりの部分が認識できませんでした。
文字が小さい原稿は、解像度を高くして読みこむほうが、拡大コピーをして読みこむよりも認識率が高いようです。コピーをすると文字の輪郭がゆがんでしまうのが原因ではないかと思います。
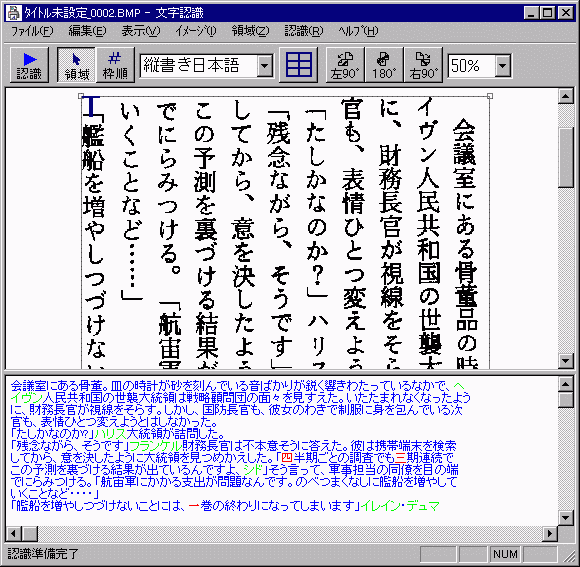
参考として、早川書房刊の『新艦長着任 上(紅の勇者オナー・ハリントン1)』の冒頭ページをOCRした結果とその画像を掲載します。
結果については、生成されたテキストファイルをそのままリンクしています。
最終更新日:1999.02.16 12:57:08
作成者:高橋 秀雄 hd5h−tkhs @ asahi−net.or.jp
Copyright 1999
 続いて、原稿の読み取りを行います
続いて、原稿の読み取りを行います{kind=link}
{kind=link}
{kind=link}